警告,包含大量GPT4分析和代写内容,可能存在谬误
原仓库地址:https://github.com/Keytoyze/Mug-Diffusion
(1)数据集准备部分
数据准备过程概况如下:
- 把下载好的数据集(osu谱面)放在
data/文件夹下,可以准备一个子文件夹 - 数据集文件夹下新建一个beatmap.txt,记录谱面元数据,用于下一步
- 按照configs/mug/mania_beatmap_features.yaml中的配置,抽取谱面的特征
- 谱面特征需要转化为数据表,存放与beatmap.txt同一目录下的features.db数据库中
- 至少准备两个这样的数据集:一个训练集一个验证集
[mug/data]
mug/data/convertor.py: 工具类,用来解析单个.osu谱面文件
mug/data/dataset.py: 构建用于pytorch训练的数据集格式,在此之前,请确保已经抽取了谱面特征,并存放在features.db中
mug/data/utils.py: (待分析)一些用于对齐的工具函数
准备好的数据集条目示例:
1 | { |
- note:谱面音符的数据(文本 -> 向量)
- feature:谱面特征的数据,osu元数据和ett分数等 (文本 -> 向量)
- audio:音频的张量数据 (有一个问题是,模型是怎么处理长度不同的音频的?)
- valid_flag:
?一个标记向量,用于标记谱面中的音符是否有效,即是否在音频中有对应的音符?
1 | # 数据集中各张量的shape |
处理音频的缓存.npz文件放置于data/audio_cache文件夹中。
[scripts]
- 如果我的判断没错,准备数据这个阶段时完全手动的,看到这个文件夹下的脚本都没有被引用过……
scripts/prepare_beatmap.py: 用本地下载的osu谱面于制作beatmap.txt,给定输入输出文件夹
scripts/prepare_ranked_beatmap.py: 从osu网站上爬取谱面,制作beatmap.txt,需要用到kuit自己的网站服务
scripts/prepare_beatmap_from_ranking_mapper.py: 同上,不过似乎是从特定的谱师id中获取
scripts/prepare_beatmap_features.py: 从beatmap.txt中读取谱面元数据,抽取谱面特征,并提交到features.db中
抽取特征需要以下参数:
1 | beat_map_path = beatmap.txt 文件的路径,记得铺面文件的存放位置与该txt位于同一目录 |
scripts/filter_beatmap.py: (待分析)似乎是用于过滤谱面中的变速
……
其他脚本似乎是用于处理Etterna谱面的,或者是一些用于算法测试的(破案了,是原来stable diffusion的一些测试代码),跳过这一部分
数据集配置
如果你要训练,必须准备基本的两个数据集文件夹:
mug.data.dataset.OsuTrainDatasetmug.data.dataset.OsuVaildDataset
将数据集路径指定在训练用的配置文件中,目前的路径是configs/mug/mug_diffusion.yaml,
同时最好有一个mug.data.dataset.OsuTestDataset数据集,用于测试.
训练数据集示例结构:
TODO
(2)VAE编解码部分
这部分的目的是为了得到两个模型:
- Encoder:将谱面信息编码为一个向量
- Decoder:将一个向量解码为谱面信息
[mug/firststage]
这部分用于实现AutoEncoder,自动编码器是一种无监督学习的神经网络模型,主要用于学习输入数据的压缩表示
AutoEncoder的结构如下:
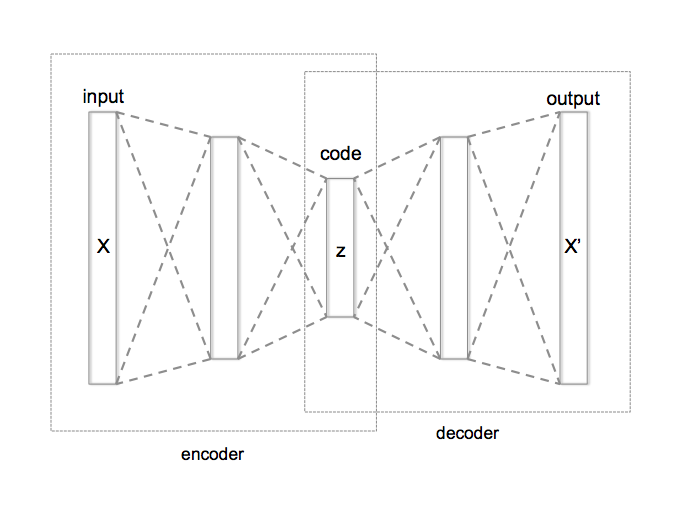
其中包含两个torch.nn.Module类的组件:编码器(Encoder)和解码器(Decoder)。编码器的作用是将输入数据压缩为一个低维度的表示,而解码器则将这个低维度的表示恢复为原始的高维度数据
注意:mug/firststage/autoencoder.py中的部分模型使用的网络模块定义在mug/model/modules.py中
Encoder模型结构:
- 输入通道数C=16
- 经过一个3*3的卷积层,输出中间通道数64
- 经过一系列下采样操作:在每次下采样之前,先经过一个残差块,并让每两次下采样后,网络的通道数翻倍
- 即: 64 * [1,1,2,2,4,4]
- 下采样网络:可选 卷积 或 平均池化
- 卷积:3*3卷积层,stride=2
- 平均池化:2*2平均池化层,stride=2
- 中间层:使用2个残差块,每个残差块包含两个3*3卷积层,通道数不变
- 输出层:首先通过一个归一化层对数据进行归一化处理,然后通过一个33卷积层将数据的通道数转换为编码器的输出通道数,输出 目标输出通道数2 的向量表示
- 如:目标输出通道数为32,则输出64维的向量表示
Decoder模型结构:
与Encoder模型结构正好相反,先将输入向量卷积到中间层,然后再经过一系列上采样操作,最后经过归一化和一个3*3卷积层,输出目标输出通道数的向量表示
损失函数:AutoEncoderKL类使用了两个损失函数,分别是重构损失和KL散度损失
- 重构损失:在
mug/firststage/losses.py中定义,计算重构的谱面数据与原始谱面数据的误差,包括多种误差计算方式 - KL损失:计算编码器输出的均值和方差与标准正态分布的KL散度
- KL损失在加入总损失时,需要乘以一个权重系数
self.kl_weight,默认为0(不考虑KL损失)
- KL损失在加入总损失时,需要乘以一个权重系数
AutoEncoder模型的使用:
参见下面diffusion的部分
(3)Diffusion训练部分
条件嵌入模型 [mug/cond]
mug/cond这个文件夹里实现的都是条件编码模型,即将谱面的特征提示信息和音频信息一起编码,然后输入Diffusion模型的去噪过程,用来控制输出结果的条件向量。
特征输入:特征定义在符合yaml格式的文本上,里面的信息包括如 难度sr,long note比例,键形特征等,训练时特征存储在数据集的database里,推理是可以手动输入,或是从一张想要参考的谱面中提取出来
音频输入:通过频谱变换离散化后的音频数据,有多种处理方式
noise level:[不知道这个是在哪里被嵌入的……]
feature_cond.py - BeatmapFeatureEmbedder 谱面特征(提示)嵌入
主要模型为BeatmapFeatureEmbedder的类,该类继承自torch.nn.Module,用于实现特征编码和嵌入。
这里嵌入的特征是谱面元数据,即configs/mug/mania_beatmap_features.yaml中定义的特征。该文件路径需要作为参数传入的构造函数中。
读入mania_beatmap_features.yaml文件的信息后,会使用mug/util.py中的count_beatmap_features函数,计算每个特征需要在嵌入向量中用几个值来表示,例如,一个bool类型的特征需要3个值(表示True/False或者没有这个特征)。
使用 torch.nn.Embedding创建一个嵌入层self.embedding,其维度为传入的参数的embed_dim。
1 | def __init__(self, path_to_yaml, embed_dim): |
forward方法是模型的前向传播过程。它接收一个输入x,将其转换为长整型,然后通过嵌入层进行转换。最后,使用rearrange函数调整张量的维度顺序。
pattern解释: 输入时二维向量,其形状为[B, F],其中B代表批次大小,F代表特征数量。
经过嵌入层后,输出的形状为[B, F, H],其中H代表嵌入向量的维度,即参数embed_dim。
1 | def forward(self, x): |
summary方法使用torchsummary库的summary函数,打印出模型的概要信息,包括输出大小、参数数量、内核大小等。
1 | def summary(self): |
测试:输入一个特征配置文件,打印出模型的概要信息。
1 | if __name__ == '__main__': |
wave.py - 音频数据嵌入
- 这里定义了
STFTEncoder,MelspectrogramEncoder等模型,主要实现将音频信息编码为嵌入向量- STFTEncoder类是一个音频编码器,使用了短时傅里叶变换(STFT)进行音频编码。
- MelspectrogramEncoder和MelspectrogramEncoder1D类是另外两种音频编码器,使用了梅尔频谱图(Melspectrogram)进行音频编码。
- S4BidirectionalLayer类是一个双向S4模型层,它包含了一个归一化层和一个双向S4模型。
- TimingDecoder类是一个解码器,它用于将编码后的音频数据解码回原始数据
- MelspectrogramScaleEncoder1D类是一个一维的梅尔频谱图编码器,它使用了注意力机制进行音频编码。
实际模型训练时,通过指定yaml配置文件中的wave_stage_config字段选择音频编码模型。
在已知的两种的配置中,编码音频分别使用了STFTEncoder和MelspectrogramScaleEncoder1D模型,分别对应配置文件mug_diffusion_stft.yaml
和mug_diffusion.yaml
LDM/DDPM模型 - [mug/diffusion]
模型训练使用的是Pytorch-Lightning框架,这是一个pytorch深度神经网络api的抽象和包装。它的好处是可复用性强,易维护,逻辑清晰等。
主要的代码结构(本项目主要在mug目录下):
1 | -mug/ |
diffusion.py - DDPM模型
mug/diffusion/diffusion.py是扩散模型的核心文件,根据DDPM论文的方法实现了整个框架模型,因此类名也叫DDPM:
DDPM继承了pl.LightningModule类。一个继承了pl.LightningModule的类被称为Lightning Module,需要实现以下三个核心的组件:
- 1 模型:
self.model,训练用的模型网络,可嵌套torch.nn.Module类型 - 2 优化器:实现
configure_optimizers()函数,其返回值可以是一个优化器或数个优化器,又或是两个List(优化器,Scheduler) - 3 训练步骤:实现以下函数:
forward()函数,定义前向转播过程,返回如何计算损失,这是用来做梯度下降的training_step()函数,这个函数其实是包装了一个pytorch的训练过程(就是一个for循环,如果你学过基础的pytorch神经网络实现的话)
其接收一个batch的来自训练数据集的数据,然后,通常这个函数会调用类自身(self(batch)),来通过已定义的模型对整个批量进行一步推理,
然后根据forward()中的定义计算loss损失。- 需要返回一个字典,包含
loss和log两个字段。loss返回损失,log则是可选的,记录一些需要记录的信息,loss字段一定要存在,
否则pytorch lightning会认为此batch是无效的,从而被跳过训练部分。
- 需要返回一个字典,包含
validation_step()函数:[可选]。功能和training_step()函数一样,不过是在验证过程中调用的,不会去更新模型的权重,只输出log信息,
主要是给你一个工具,用来自定义输出验证过程中要观察的变量的。training_epoch_end()函数:[可选]。这个函数是在每个epoch结束时调用的,用于记录一些信息,比如训练集的平均损失等。
回到DDPM类本身,在定义模型时,使用的语句是:
1 | # mug/diffusion/diffusion.py |
这里,额外定义了一个MugDiffusionWrapper类,用来包装MuG Diffusion模型中包含的四个子模型,分别是:
- cond_stage_model:前文所述的
BeatmapFeatureEmbedder模型,用来得到【谱面提示】的压缩表示(由可读数据压缩到向量)- 谱面数据包含 osu的谱面元数据(难度等)和 通过minacalc计算得到的谱面提示(各个键形的分布、键形难度等),不包含note数据
- wave_model:前文所述的
STFTEncoder或MelspectrogramScaleEncoder1D模型,用来编码和解码【音频波形】(由音频数据到条件向量?) - first_stage_model:前文所述的
AutoEncoderKL模型,用来编码和解码 【谱面note数据】(从 向量 编码到 潜空间向量 和 从 潜空间向量 解码) - unet_model:与Stable Diffusion类似的U-Net结构,用来学习反向扩散去噪(Denosing)的步骤
- 即,unet_model接受潜空间的两种输入:1、【潜空间的谱面向量数据】2、【条件嵌入向量,包括音频和谱面特征(即“提示 prompt”)】,
通过多步扩散迭代,学习正向扩散参数,或是反向扩散输新的谱面向量表示。- 在训练时,unet_model的输入是一个【训练数据集的谱面潜空间向量】和【该谱面对应的音频向量、提示向量】,输出是一个【潜空间向量】,
每一次迭代,都会使得【潜空间向量】接近于从高斯分布采样的【噪声数据】,并同时更新网络权重 - 在推理生成新谱面时,unet_model的输入是一个【从高斯分布种采样的噪声谱面向量】和【用户想要的谱面音频和特征的输入向量】,通过多次反向扩散,
得到生成的【谱面潜空间向量】,通过first_stage_model解码得到可读的【谱面note数据】 -
每个模型的详细结构在下一个小节描述
- 在训练时,unet_model的输入是一个【训练数据集的谱面潜空间向量】和【该谱面对应的音频向量、提示向量】,输出是一个【潜空间向量】,
- 即,unet_model接受潜空间的两种输入:1、【潜空间的谱面向量数据】2、【条件嵌入向量,包括音频和谱面特征(即“提示 prompt”)】,
对比:Stable Diffusion(v1)的模型模块和 MuG Diffusion的模型模块
| 输入编码器(条件嵌入) | 潜空间扩散网络 | 输出解码器 | |
|---|---|---|---|
| Stable Diffusion | 基于 CLIP 模型的文本编码器 | U-Net | AutoEncoder(图像) |
| MuG Diffusion | 基于STFT/Mel的音频编码器 + 谱面提示嵌入 | U-Net(魔改) | AutoEncoder(谱面Note) |
DDPM使用的优化器是AdamW,如果yaml配置文件中定义了学习率调度器,还会使用Pytorch的LambdaLR创建一个学习了调度器。
1 | # mug/diffusion/diffusion.py |
在MuG Diffusion的两种配置文件里,
mug_diffusion.yaml中定义了学习率调度器为Stable Diffusion使用的
ldm.lr_scheduler.LambdaLinearScheduler,而mug_diffusion_stft.yaml中没有定义学习率调度器
unet.py - U-Net模型
mug/diffusion/unet.py中定义了U-Net模型,这个模型是DDPM的核心,用于进行潜空间的扩散和反向扩散。
wave_model、cond_stage_model和first_stage_model(即VAE)的输出都将作为U-Net的输入,下面从模型输入和输出的shape简要描述一下模型。
1 | # mug/diffusion/diffusion.py |
整个网络的结构遵循UNet的典型编码器-解码器结构,通过逐渐增加和减少特征图的尺寸来学习丰富的特征表示,最终输出与输入相同尺寸的张量。
U-Net模仿了Stable Diffusion中的U-Net结构,包括注意力层等,但是做了一些改动,主要是为了适应【音频数据具有天然的时序性】。
Stable Diffusion U-Net的结构参见(图源水印):
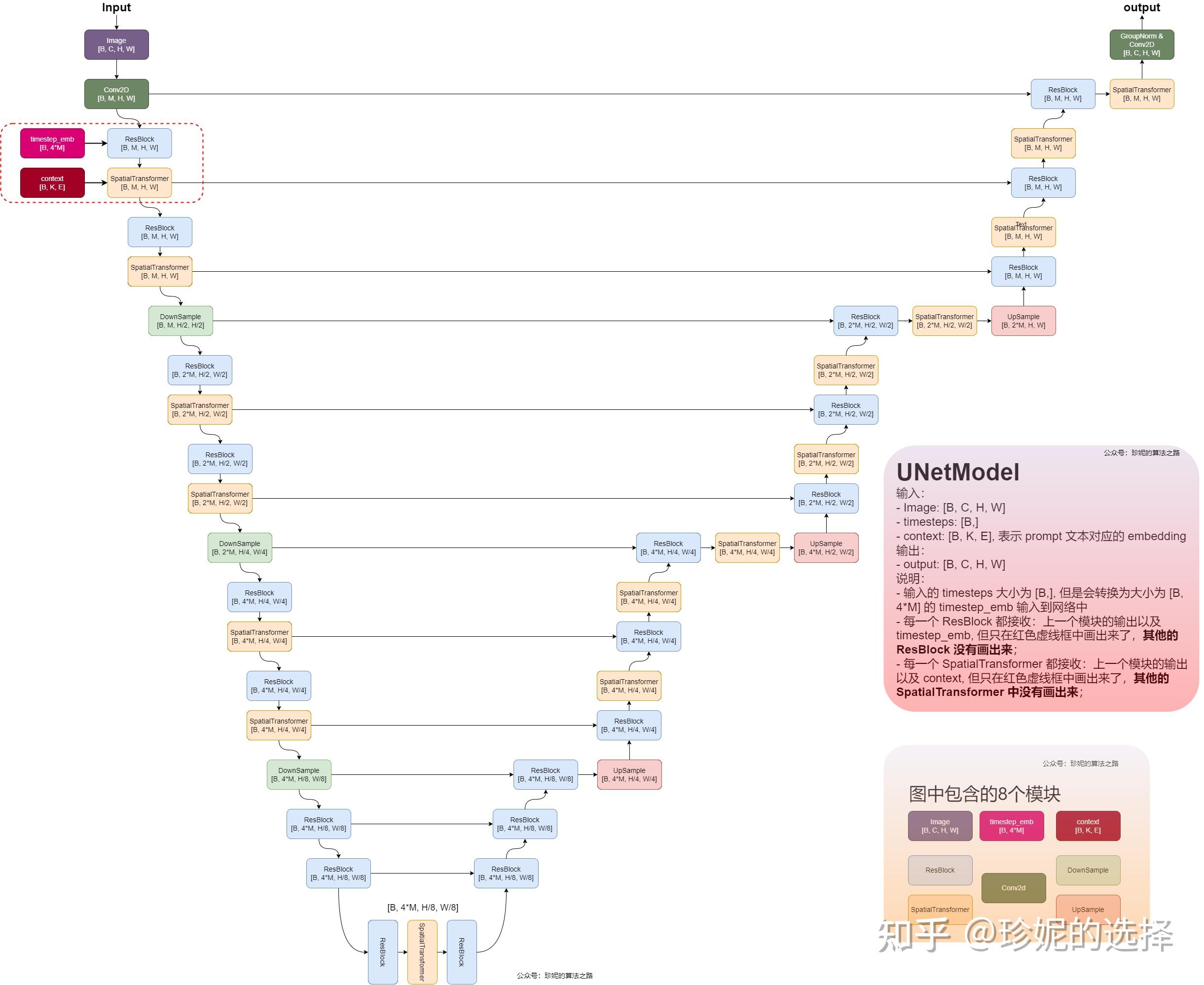
因此,U-Net模型中可以选择加入下面的部分来增强模型处理序列数据的能力。
- LSTM层,使用LSTM模型处理时序信息,这也是参考已有生成谱面的工作,大多采用了LSTM块来设计网络。
- S4层:使用Structured State Space(S4)模型,是一种基于状态空间模型(SSM)的新型序列建模方法。它本质上是连续时间的,并且在建模数据中的长期依赖性方面表现出色。
模型结构流程描述:
- [ i ] 首先进行一个卷积,将输入张量数据(谱面note数据)的通道数转换为
model_channels
(model_channels是配置文件中定义的参数(128),代表模型的通道数)。 - [ ii ] Downstamps(input_blocks) 下采样:"U“形状的左半边,每次通过两个网络模块:
-
1、
AudioConcatBlock,将当前分辨率等级的音频通道数直接加到到模型的通道数中,并连接音频数据和输入数据。
音频通道数对于不同的采样分辨率分别是[256,512,512,512] -
2、一个ResBlock(残差块),其中包含三层:
- 第一
TimestepResBlock,和Stable Diffusion的方法一样,将时间步数据嵌入到残差块中(没细看,不知道这里有没有魔改…… - 第二
ContextualTransformer(自定义注意力层), - 第三:按照配置中的指定,在注意力层中后面额外添加一个LSTM层或S4层。
- 第一
-
每个
TimestepResBlock都会从外部连接一个timestep_emb,作为时间信息的编码。这里采用了和Stable Diffusion一样的策略,
timestep_emb的长度为model_channels的4倍。 -
每个
ContextualTransformer层都会从外部连接一个相同的context张量,这个就是之前传入的c,从BeatmapFeatureEmbedder获得的谱面特征提示数据在原版Stable Diffusion里,注意力块名称是SpatialTransformer,因为生成图像的文本提示contex是不定长的,而这里生成谱面的提示是定长的,
且不需要进行2D卷积。因此这里重新写了一个ContextualTransformer,二者都是从BasicTransformerBlock继承而来。 -
每次通过完整的input_block以后,进行一次下采样,倍增模型的通道数(按照配置,倍率为[ 1,2,4,4 ]),压缩数据的维度和注意力层的分辨率
-
- [ iii ] middle_block: "U"形状的底部,也是模型的中间层,与Stable Diffusion的结构仍然相同,通过了一个三明治形状的
TimestepResBlock-ContextualTransformer-TimestepResBlock网络块。 - [ iv ] Upstamps(output_blocks) 上采样:"U"形状的右半边,老样子,与下采样相反即可,每次通过相同的
TimestepResBlock-ContextualTransformer-LSTM/S4层后进行一次上采样。 - [ v ] 输出层:上采样结果先通过一个归一化层和一个SiLU激活函数,然后最后通过一个卷积层将特征映射到目标输出通道数,over。
好奇:这里和原版SD一样,用了个
zero_module来初始化卷积层,不知是什么优化技巧……
各个模型的input size和Output size:
下表默认省略了batch size,即应该添加在各个input size前面的批量维度B
| 模型 | Input size | Output size | 备注 |
|---|---|---|---|
| (VAE)Encoder | (16, 4096) | (64, 128) | 16是谱面note数据的输入通道数,它是由“4K”按键的四个位置,每个位置分配4个通道构成的。 经过多次下采样后得到形状256*128,然后通过卷积压缩到潜空间的形状为64*128 |
| (VAE)Decoder | (64, 128) | (16, 4096) | 与上面相反,多次上采样后得到形状64*4096, 然后通过卷积恢复到谱面形状16*4096 |
| BeatmapFeatureEmbedder | (f) | (f, 128) | f是feature的数量?(数据集中一个谱面的feature长度为21) |
| MelspectrogramScaleEncoder1D | (128, 32768) | (512, 64) | 32768代表最大的序列长度(梅尔频谱图的长度),和下面的傅里叶变换相比,是将两个音频通道混合到一起,数量*2 |
| STFTEncoder | (2, 1025, 16384) | (32, 256) | 2=输入通数道(对应复数的实部和虚部),1025=频率分辨率,16384=最大的序列长度,输出形状中的32是输出通道数 |
| U-Net(使用STFT) | (544, 4096) | (32, 4096) | 在这个方法中,音频通道和输入通道(32)一开始就通过直接连接合并到一起,544 = 512+32 (我也不知道为什么使用STFT的通道数多一倍,对不起我没学过信号处理QAQ) |
| U-Net(使用MelScaleEncoder1D) | (16, 4096) | (16, 4096) | x是从噪声分布中采样的,与谱面note数据形状相同的随机输入。 而提示数据、时间步数据和音频数据都是从外部嵌入的。 |
ddim.py - DDIM模型
DDIM是DDPM的一个改进模型,用于推理时快速采样x,貌似训练时没有用到。
训练入口[main.py]
- 加载模型:
model = instantiate_from_config(config.model),config里配置的模型即为DDPM模型 - 加载数据:
1 | data = instantiate_from_config(config.data) |
- 开始训练,使用
trainer.fit()函数,传入模型和数据集
1 | if opt.train: |
(4)WebUI和推理部分
交互式推理入口[webui.py]
TODO
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 许可协议,转载请注明出处。



